Automated testing makes software quality checks faster and more consistent, but end-to-end tests carry an inherent trade-off: they are brittle. As soon as developers update features or requirements shift, tests break. What was meant to speed teams up frequently slows them down with endless rework and maintenance.
Every test strategy balances three things: stability, reliability, and adaptability. Stability means tests behave the same way every time, reliability means results match how the product actually works, and adaptability means tests keep up as the product evolves. Traditional automation forces trade-offs. It delivers stability and reliability in the short term but falls short on adaptability, leaving humans to handle the slow, manual work of updating tests.
AI agents don’t make E2E tests less brittle; tests still break when features or flows change. Instead, agents absorb most of the maintenance work that brittleness creates. By adapting in real time and recognizing patterns, agents can keep tests stable and results reliable while shifting the cost of brittleness away from QA engineers and preventing them from rewriting code. In this way, adaptability reinforces stability and reliability instead of undermining them.
AI agents are quickly becoming a part of modern testing strategies, making it important to understand what they are, how they work, and where their limits lie.
What is an AI agent?
An AI agent is an autonomous (or semi-automonous) system that’s given a goal and determines how to achieve it without a human directing each step. It observes its environment, reasons about possible actions, uses tools to act, and adapts based on feedback. Unlike fixed workflows, agents dynamically decide what to do next rather than following a predefined sequence.
How are AI agents different from LLMs and AI workflows?
These terms are often used interchangeably, but they mean different things. LLMs, workflows, and agents are related—each one builds on the other—but they function in distinct ways. Understanding these differences is essential to seeing what makes agents important.
The building blocks: LLMs (large language models)
Models like ChatGPT that generate text, code, or ideas when prompted. They don’t act on their own or retain context across tasks unless given it. They are passive, waiting for input (prompts) before producing output.
Connecting the building blocks: AI workflows
Structured pipelines where multiple AI components are connected in a sequence. Workflows can branch or vary within rules defined ahead of time, but they don’t adapt beyond those rules. That said, they handle repetitive tasks more consistently than LLMs, but they remain limited by those rules.
The step beyond: AI agents
Goal-driven systems that observe, plan, act, and adapt in a feedback loop. Agents use multiple inputs, including but not limited to tools and data, to decide what to do next based on outcomes, not just predefined sequences, which makes them more flexible than workflows.
Here’s how they differ: LLMs generate but don’t act. Workflows add structure and efficiency but stay inside fixed boundaries. Agents go further: They pursue goals, make decisions dynamically, and adapt when conditions change.
What is an agent’s job?
An agent’s job is to deliver an outcome, not just run through steps. It pursues a goal by observing conditions, choosing actions, and adjusting based on results.
Humans set the goal, not the script. The agent figures out the best way to achieve it. Success is measured not by “did the steps run?” but “was the goal accomplished?” By taking on the unpredictable parts of the work, agents let teams stay focused on defining what matters instead of micromanaging how to get there.
How do AI agents work?
AI agents act as decision-makers inside a larger agentic system, but they don’t work in isolation. They interact with specialized components, which may include executors, data or memory modules, coordinators, or even other agents in a multi-agent setup. These components allow an agent to turn reasoning into concrete actions.
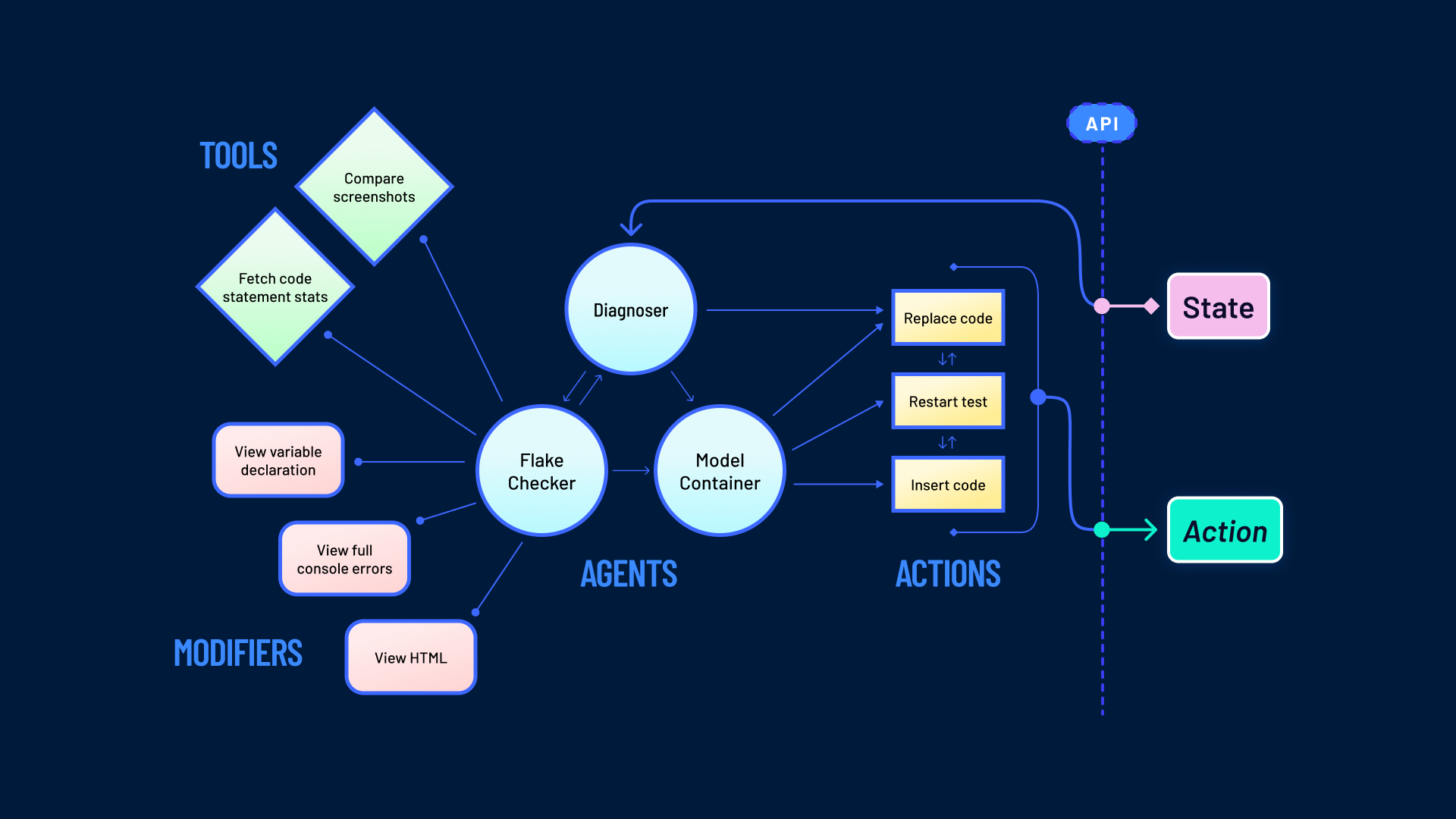
At a minimum, agents need mechanisms to:
- Take actions that change the system’s state, such as running code, fixing an error, or updating a record.
- Manage control flows, deciding when to continue, stop, or loop back.
- Call external tools that fetch data or context from external sources, like APIs, databases, or search engines.
- Call internal tools (aka modifiers) that adjust the level of detail available, helping agents zoom in or out depending on the task.
Under the hood, more advanced systems often layer in specialized functions:
- RAG (retrieval-augmented generation) to ground decisions in real product or domain knowledge.
- Memory management to store and recall past interactions or state so agents can maintain continuity across tasks.
- Fine-tuning to adapt models to domain-specific data for higher accuracy and reliability.
- Repeated execution to re-run actions until conditions are met.
Not every agent uses all of these. Some systems remain simple and rule-driven, while others incorporate more advanced capabilities. But taken together, these components show how agents can move from reasoning to reliable action in dynamic environments.
What are the types/styles of AI agents?
AI agents fall into two broad categories—single agents and multi-agent systems—and within those, into distinct styles based on how they make decisions.
- Single agents operate independently to pursue a goal.
- Multi-agent systems operate as a network of agents, each with a specialized role.
Within these categories, agents can be further classified by decision-making style:
- Simple reflex agents: React to predefined rules with no memory or internal state. They break easily with UI or API changes and lack adaptability.
- Model-based agents: Maintain an internal state of the environment. They can act beyond simple reflexes but do not explicitly plan toward goals.
- Goal-based agents: Act to achieve a specified outcome. They succeed when goals are clear but lack a way to compare alternatives if multiple actions could work.
- Utility-based agents: Make decisions based on a utility function that defines what is most valuable. They compare options and choose the action with the highest expected benefit.
- Learning agents: Adapt behavior over time from past results. Their effectiveness depends on feedback data—garbage in, garbage out.
Agents can be applied anywhere and even combined, but automated software testing is especially well-suited because the work is ongoing, repetitive, and sensitive to change.
Why do you need an agentic system for QA testing?
The biggest challenge in QA is maintenance: products evolve, selectors break and environments change. Non-agentic systems can fix issues in the moment, but they don’t hold enough context to manage long-term upkeep. It can’t consistently remember why a test broke or prevent it from breaking again.
Agentic systems track changes over time, preserve history, and change tests to correspond with product updates. By keeping tests up-to-date and accurate, agentic systems reduce the constant maintenance burden that slows down teams.
How do AI agents support the QA lifecycle?
Agents take on the day-to-day maintenance work that makes QA costly and time-consuming. Unlike traditional automation that focuses on individual tests, agents can reason about the entire suite. By seeing the greater context, they can spot systemic issues, reduce duplication, and guide maintenance at a higher level.
They do this by applying their reasoning to the core tasks of QA:
- Test case generation: Agents translate requirements, specs, or recordings into prompts or executable test cases.
- Test data management: Agents handle data seeding, authentication/SSO flows, and secrets so tests run reliably across environments.
- Automated execution: Agents orchestrate test runs across browsers, devices, environments, and CI/CD pipelines.
- Test maintenance and self-healing: Agents repair broken selectors or update tests when applications change, reducing manual upkeep.
- Failure triage: Agents classify results as bugs, infrastructure issues, or flaky tests.
- Debugging support: Agents capture logs, screenshots, and telemetry automatically, giving teams the context they need for faster root-cause analysis.
- Exploratory testing: Agents probe unscripted flows to uncover issues that scripted cases would miss.
- Performance, security, and accessibility testing: Agents extend beyond functional testing to run adaptive load and stress tests, probe for vulnerabilities, and enforce accessibility rules.
Together, these capabilities result in reduced repetitive effort, expanded coverage, and accurate test suites as products evolve.
What specific agents and tools did QA Wolf develop for E2E testing?
To handle the brittleness of E2E testing, QA Wolf built a multi-agent system with more than 150 specialized agents. Each agent is trained for a specific responsibility in creating and maintaining tests, coordinated by an Orchestrator that manages workflows and directs information flow.
The Outliner generates detailed test plans and AAA outlines by analyzing product tours and capturing client testing goals from audio. The Code Writer turns those outlines into Playwright code, trained on over 700 gym scenarios distilled from 40 million test runs. The Verifier then executes the generated code to ensure it behaves as intended.
Supporting capabilities extend these agents further. Intelligent history summarization captures and condenses what happened at each step, making it easier to track and audit the evolution of a test. A built-in decision layer evaluates all relevant information in real time, much like a QA engineer would when troubleshooting a broken test.
These agents are built on top of LLMs and extended with QA-specific training and structure, making them flexible enough to adapt while precise enough to handle the unique demands of E2E testing.
How should AI agents be trained and measured?
For agents to be useful in QA, they have to work as quickly and as accurately as a skilled human engineer. Anything less makes them a burden, not a help. That’s the yardstick every agent should be measured against.
Training and measurement are two sides of the same loop. Agents have to be tested on full tasks—not just isolated steps—to show they can perform the work of creating and maintaining tests. At QA Wolf, this starts with simulated gym environments that replicate real QA challenges. We prioritize high-value scenarios that mirror the problems engineers face most often, then expand coverage over time.
We use weighted metrics to score performance, where the most critical tasks count more toward overall results than minor ones. The system logs failures, analyzes them, and turns them into new training scenarios. This creates a continuous feedback cycle: Every error highlights a gap, and every new scenario improves accuracy and reliability. QA engineers reinforce this loop by using and evaluating the agents daily, providing corrections that speed up learning.
Efficiency matters too. By focusing on the 5% of scenarios that uncover 95% of problems, we save time and cost while keeping training data relevant to real-world QA.
Measured against the human standard and refined through this loop, agents become more dependable the longer they run. Training and measurement are part of the same process— agents improve while proving their effectiveness.
Why AI agents are critical for QA
AI agents are critical because they take on the maintenance burden that makes E2E testing unsustainable. They manage the brittleness of test suites, keeping them reliable as products evolve and shifting the cost of upkeep away from engineers.
The bigger change is what this enables. Freed from constant maintenance, QA teams can expand coverage, catch issues earlier, and accelerate releases. Agents don’t just reduce upkeep—they make long-term reliability sustainable. For teams, that’s the real payoff: a path out of maintenance churn and toward faster, more confident delivery.